After reading "Feature Visualization" you may be curious what other channels of GoogLeNet look like.
Below, you can click on the layer names to see all units of that layer. You can learn more about individual examples by clicking on them, too. Or just browse this overview first to get a sense of which layers you'd like to explore. We recommend layer 4c!
Layer 3a




This first inception layer already shows some quite interesting textures. Each neuron only looks at a small receptive field, so these channel visualizations show you a tiling of them.
Layer 3b



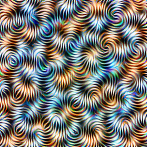
Textures become more complex, but are still very local.
Layer 4a
 Bookshelves
Bookshelves Dog eyes
Dog eyes Text, rivets
Text, rivets Birds
BirdsIn this layer, which follows a pooling step, we see a signficant increase in complexity. We begin to see more complex patterns, and even parts of objects.
Layer 4b
 Architecture
Architecture Fluffy rope
Fluffy rope Trees
Trees Billiard balls
Billiard ballsAlready you can begin to make out parts of objects — such as the billiard ball detector on the right here. Visualizations start having more context, like the neuron on the second from the right which responds to trees in front of sky and ground.
Layer 4c
 Palm trees
Palm trees Wheels
Wheels Dogs on leash
Dogs on leash Houses
Houses
In this layer things get complex enough that it can often help to look at the neuron objective rather than the channel objective.
You can find neurons responding to dogs on leashes only, many wheel detectors, and a lot of other fun neurons.
This is likely the most rewarding layer to start exploring!
Layer 4d
 Dog snouts
Dog snouts Primates
Primates Snake heads
Snake heads Restaurant dishes
Restaurant dishesBy this layer we find more sophisticated concepts, like a particular kind of animal snout. On the other hand, we also start to see neurons that react to multiple unrelated concepts. It helps to look at the diversity and dataset examples to double check what a neuron reacts to.
Layer 4e
 Turtle shells
Turtle shells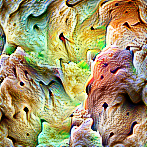 Icecream & bread
Icecream & bread Cat fur
Cat fur Sombreros
SombrerosAt this level, many neurons will differentiate between specific animal species or react to multiple concepts. These are, however, usually still visually similar, which can lead to funny situations like reacting to both satellite dishes and sombreros. One can also still find texture detectors, though they usually react to more complex textures such as icecream, bread and cauliflower. The first neuron example here predictably reacts to turtle shells, but interestingly also to fretted instruments.
Layer 5a
 Candles
Candles Balls
Balls Brass instruments
Brass instruments Traffic lights
Traffic lightsVisualizations become harder to interpret here, but the semantic concepts they target are often still quite specific.
Layer 5b




In this layer visualizations become mostly nonsensical collages. You may still identify specific subjects, but will usually need a combination of diversity and dataset examples to do so. Neurons do not seem to correspond to particularly meaningful semantic ideas anymore.