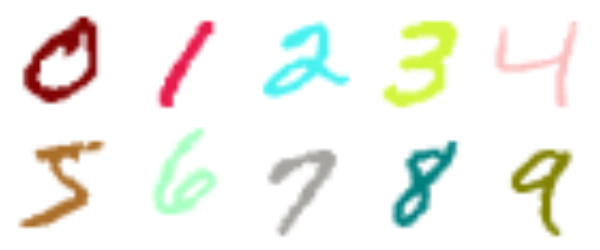This article is part of the Differentiable Self-organizing Systems Thread, an experimental format collecting invited short articles delving into differentiable self-organizing systems, interspersed with critical commentary from several experts in adjacent fields.
Self-Organising TexturesThis article makes strong use of colors in figures and demos. Click here to adjust the color palette.
In a complex system, whether biological, technological, or social, how can we discover signaling events that will alter system-level behavior in desired ways? Even when the rules governing the individual components of these complex systems are known, the inverse problem - going from desired behaviour to system design - is at the heart of many barriers for the advance of biomedicine, robotics, and other fields of importance to society.
Biology, specifically, is transitioning from a focus on mechanism (what is required for the system to work) to a focus on information (what algorithm is sufficient to implement adaptive behavior). Advances in machine learning represent an exciting and largely untapped source of inspiration and tooling to assist the biological sciences. Growing Neural Cellular Automata
In this work, we train adversaries whose goal is to reprogram CA into doing something other than what they were trained to do. In order to understand what kinds of lower-level signals alter system-level behavior of our CA, it is important to understand how these CA are constructed and where local versus global information resides.
The system-level behavior of Neural CA is affected by:
- Individual cell states. States store information which is used for both diversification among cell behaviours and for communication with neighbouring cells.
- The model parameters. These describe the input/output behavior of a cell and are shared by every cell of the same family. The model parameters can be seen as the way the system works.
- The perceptive field. This is how cells perceive their environment. In Neural CA, we always restrict the perceptive field to be the eight nearest neighbors and the cell itself. The way cells are perceived by each other is different between the Growing CA and MNIST CA. The Growing CA perceptive field is a set of weights fixed both during training and inference, while the MNIST CA perceptive field is learned as part of the model parameters.
Perturbing any of these components will result in system-level behavioural changes.
We will explore two kinds of adversarial attacks: 1) injecting a few adversarial cells into an existing grid running a pretrained model; and 2) perturbing the global state of all cells on a grid.
For the first type of adversarial attacks we train a new CA model that, when placed in an environment running one of the original models described in the previous articles, is able to hijack the behavior of the collective mix of adversarial and non-adversarial CA. This is an example of injecting CA with differing model parameters into the system. In biology, numerous forms of hijacking are known, including viruses that take over genetic and biochemical information flow
The second type of adversarial attacks interact with previously trained growing CA models by perturbing the states within cells. We apply a global state perturbation to all living cells. This can be seen as inhibiting or enhancing combinations of state values, in turn hijacking proper communications among cells and within the cell’s own states. Models like this represent not only ways of thinking about adversarial relationships in nature (such as parasitism and evolutionary arms races of genetic and physiological mechanisms), but also a roadmap for the development of regenerative medicine strategies. Next-generation biomedicine will need computational tools for inferring minimal, least-effort interventions that can be applied to biological systems to predictively change their large-scale anatomical and behavioral properties.
Adversarial MNIST CA Try in a Notebook
Recall how the Self-classifying MNIST digits task consisted of placing CA cells on a plane forming the shape of an MNIST digit. The cells then had to communicate among themselves in order to come to a complete consensus as to which digit they formed.

(a) Local information neighbourhood - each cell can only observe itself and its neighbors’ states, or the absence of neighbours.
(b) Globally, the cell collective aggregates information from all parts of itself.
(c) It is able to distinguish certain shapes that compose a specific digit (3 in the example).
Below we show examples of classifications made by the model trained in Self-classifying MNIST Digits.
In this experiment, the goal is to create adversarial CA that can hijack the cell collective’s classification consensus to always classify an eight. We use the CA model from
- Regardless of what the actual digit is, we consider the correct classification to always be an eight.
- For each batch and each pixel, the CA is randomly chosen to be either the pretrained model or the new adversarial one. The adversarial CA is used 10% of the time, and the pre-trained, frozen, model the rest of the time.
- Only the adversarial CA parameters are trained, the parameters of the pretrained model are kept frozen.
The adversarial attack as defined here only modifies a small percentage of the overall system, but the goal is to propagate signals that affect all the living cells. Therefore, these adversaries have to somehow learn to communicate deceiving information that causes wrong classifications in their neighbours and further cascades in the propagation of deceiving information by ‘unaware’ cells. The unaware cells’ parameters cannot be changed so the only means of attack by the adversaries is to cause a change in the cells’ states. Cells’ states are responsible for communication and diversification.
The task is remarkably simple to optimize, reaching convergence in as little as 2000 training steps (as opposed to the two orders of magnitude more steps needed to construct the original MNIST CA). By visualising what happens when we remove the adversaries, we observe that the adversaries must be constantly communicating with their non-adversarial neighbours to keep them convinced of the malicious classification. While some digits don’t recover after the removal of adversaries, most of them self-correct to the right classification. Below we show examples where we introduce the adversaries at 200 steps and remove them after a further 200 steps.
While we trained the adversaries with a 10-to-90% split of adversarial vs. non-adversarial cells, we observe that often significantly fewer adversaries are needed to succeed in the deception. Below we evaluate the experiment with just one percent of cells being adversaries.
We created a demo playground where the reader can draw digits and place adversaries with surgical precision. We encourage the reader to play with the demo to get a sense of how easily non-adversarial cells are swayed towards the wrong classification.
Adversarial Injections for Growing CA Try in a Notebook
The natural follow up question is whether these adversarial attacks work on Growing CA, too. The Growing CA goal is to be able to grow a complex image from a single cell, and having its result be persistent over time and robust to perturbations. In this article, we focus on the lizard pattern model from Growing CA.
The goal is to have some adversarial cells change the global configuration of all the cells. We choose two new targets we would like the adversarial cells to try and morph the lizard into: a tailless lizard and a red lizard.

These targets have different properties:
- Red lizard: converting a lizard from green to red would show a global change in the behaviour of the cell collective. This behavior is not present in the dynamics observed by the original model. The adversaries are thus tasked with fooling other cells into doing things they have never done before (create the lizard shape as before, but now colored in red).
- Tailless lizard: having a severed tail is a more localized change that only requires some cells to be fooled into behaving in the wrong way: the cells at the base of the tail need to be convinced they constitute the edge or silhouette of the lizard, instead of proceeding to grow a tail as before.
Just like in the previous experiment, our adversaries can only indirectly affect the states of the original cells.
We first train adversaries for the tailless target with a 10% chance for any given cell to be an adversary. We prohibit cells to be adversaries if they are outside the target pattern; i.e. the tail contains no adversaries.
The video above shows six different instances of the same model with differing stochastic placement of the adversaries. The results vary considerably: sometimes the adversaries succeed in removing the tail, sometimes the tail is only shrunk but not completely removed, and other times the pattern becomes unstable. Training these adversaries required many more gradient steps to achieve convergence, and the pattern converged to is qualitatively worse than what was achieved for the adversarial MNIST CA experiment.
The red lizard pattern fares even worse. Using only 10% adversarial cells results in a complete failure: the original cells are unaffected by the adversaries. Some readers may wonder whether the original pretrained CA has the requisite skill, or ‘subroutine’ of producing a red output at all, since there are no red regions in the original target, and may suspect this was an impossible task to begin with. Therefore, we increased the proportion of adversarial cells until we managed to find a successful adversarial CA, if any were possible.
In the video above we can see how, at least in the first stages of morphogenesis, 60% of adversaries are capable of coloring the lizard red. Take particular notice of the “step 500”
However, the model is very unstable when iterated for periods of time longer than seen during training. Moreover, the learned adversarial attack is dependent on a majority of cells being adversaries. For instance, when using fewer adversaries on the order of 20-30%, the configuration is unstable.
In comparison to the results of the previous experiment, the Growing CA model shows a greater resistance to adversarial perturbation than those of the MNIST CA. A notable difference between the two models is that the MNIST CA cells have to always be ready and able to change an opinion (a classification) based on information propagated through several neighbors. This is a necessary requirement for that model because at any time the underlying digit may change, but most of the cells would not observe any change in their neighbors’ placements. For instance, imagine the case of a one turning into a seven where the lower stroke of each overlap perfectly. From the point of view of the cells in the lower stroke of the digit, there is no change, yet the digit formed is now a seven. We therefore hypothesise MNIST CA are more reliant and ‘trusting’ of continuous long-distance communication than Growing CA, where cells never have to reconfigure themselves to generate something different to before.
We suspect that more general-purpose Growing CA that have learned a variety of target patterns during training are more likely to be susceptible to adversarial attacks.
Perturbing the states of Growing CA Try in a Notebook
We observed that it is hard to fool Growing CA into changing their morphology by placing adversarial cells inside the cell collective. These adversaries had to devise complex local behaviors that would cause the non-adversarial cells nearby, and ultimately globally throughout the image, to change their overall morphology.
In this section, we explore an alternative approach: perturbing the global state of all cells without changing the model parameters of any cell.
As before, we base our experiments on the Growing CA model trained to produce a lizard. Every cell of a Growing CA has an internal state vector with 16 elements. Some of them are phenotypical elements (the RGBA states) and the remaining 12 serve arbitrary purposes, used for storing and communicating information. We can perturb the states of these cells to hijack the overall system in certain ways (the discovery of such perturbation strategies is a key goal of biomedicine and synthetic morphology). There are a variety of ways we can perform state perturbations. We will focus on global state perturbations, defined as perturbations that are applied on every living cell at every time step (analogous to “systemic” biomedical interventions, that are given to the whole organism (e.g., a chemical taken internally), as opposed to highly localized delivery systems). The new goal is to discover a certain type of global state perturbation that results in a stable new pattern.

We show 6 target patterns: the tailless and red lizard from the previous experiment, plus a blue lizard and lizards with various severed limbs and severed head.

We decided to experiment with a simple type of global state perturbation: applying a symmetric matrix multiplication to every living cell at every step
We initialize with the identity matrix and train just as we would train the original Growing CA, albeit with the following differences:
- We perform a global state perturbation as described above, using , at every step.
- The underlying CA parameters are frozen and we only train .
- We consider the set of initial image configurations to be both the seed state and the state with a fully grown lizard (as opposed to the Growing CA article, where initial configurations consisted of the seed state only).
The video above shows the model successfully discovering global state perturbations able to change a target pattern to a desired variation. We show what happens when we stop perturbing the states (an out-of-training situation) at step 500 through step 1000, then reapplying the mutation. This demonstrates the ability of our perturbations to achieve the desired result both when starting from a seed, and when starting from a fully grown pattern. Furthermore it demonstrates that the original CA easily recover from these state perturbations once it goes away. This last result is perhaps not surprising given how robust growing CA models are in general.
Not all perturbations are equally effective. In particular, the headless perturbation is the least successful as it results in a loss of other details across the whole lizard pattern such as the white coloring on its back. We hypothesize that the best perturbation our training regime managed to find, due to the simplicity of the perturbation, was suppressing a “structure” that contained both the morphology of the head and the white colouring. This may be related to the concept of differentiation and distinction of biological organs. Predicting what kinds of perturbations would be harder or impossible to be done, before trying them out empirically, is still an open research question in biology. On the other hand, a variant of this kind of synthetic analysis might help with defining higher order structures within biological and synthetic systems.
Directions and compositionality of perturbations
Our choice of using a symmetric matrix for representing global state perturbations is justified by a desire to have compositionality. Every complex symmetric matrix can be diagonalized as follows:
where is the diagonal eigenvalues matrix and is the unitary matrix of its eigenvectors. Another way of seeing this is applying a change of basis transformation, scaling each component proportional to the eigenvalues, and then changing back to the original basis. This should also give a clearer intuition on the ease of suppressing or amplifying combinations of states. Moreover, we can now infer what would happen if all the eigenvalues were to be one. In that case, we would naturally have resulting in a no-op (no change): the lizard would grow as if no perturbation was performed. We can now decompose where D is the perturbation direction () in the “eigenvalue space”. Suppose we use a coefficient to scale D: . If , we are left with the original perturbation and when , we have the no-op . Naturally, one question would be whether we can explore other values for and discover meaningful perturbations. Since
we do not even have to compute eigenvalues and eigenvectors and we can simply scale and accordingly.
Let us then take the tailless perturbation and see what happens as we vary :
As we change to we can observe the tail becoming more complete. Surprisingly, if we make negative, the lizard grows a longer tail. Unfortunately, the further away we go, the more unstable the system becomes and eventually the lizard pattern grows in an unbounded fashion. This behaviour likely stems from that perturbations applied on the states also affect the homeostatic regulation of the system, making some cells die out or grow in different ways than before, resulting in a behavior akin to “cancer” in biological systems.
Can we perform multiple, individually trained, perturbations at the same time?
Suppose we have two perturbations and and their eigenvectors are the same (or, more realistically, sufficiently similar). Then, and .
In that case,
would result in something meaningful. At the very least, if , setting would result in exactly the same perturbation.
We note that and are effectively a displacement from the identity and we have empirically observed how given any trained displacement , for adding results in a stable perturbation. We then hypothesize that as long as we have two perturbations whose positive directions are , this could result in a stable perturbation. An intuitive understanding of this is interpolating stable perturbations using the direction coefficients.
In practice, however, the eigenvectors are also different, so the results of the combination will likely be worse the more different the respective eigenvector bases are.
Below, we interpolate the direction coefficients, while keeping their sum to be one, of two types of perturbations: tailless and no-leg lizards.
While it largely achieves what we expect, we observe some unintended effects such as the whole pattern starting to traverse vertically in the grid. Similar results happen with other combinations of perturbations. What happens if we remove the restriction of the sum of s being equal to one, and instead add both perturbations in their entirety? We know that if the two perturbations were the same, we would end twice as far away from the identity perturbation, and in general we expect the variance of these perturbations to increase. Effectively, this means going further and further away from the stable perturbations discovered during training. We would expect more unintended effects that may disrupt the CA as the sum of s increases.
Below, we demonstrate what happens when we combine the tailless and the no-leg lizard perturbations at their fullest. Note that when we set both s to one, the resulting perturbation is equal to the sum of the two perturbations minus an identity matrix.
Surprisingly, the resulting pattern is almost as desired. However, it also suffers from the vertical movement of the pattern observed while interpolating s.
This framework can be generalized to any arbitrary number of perturbations. Below, we have created a small playground that allows the reader to input their desired combinations. Empirically, we were surprised by how many of these combinations result in the intended perturbations and qualitatively it appears that bounding to one results in generally more stable patterns. We also observed how exploring negative values is usually more unstable.
Related work
This work is inspired by Generative Adversarial Networks (GANs)
The kinds of state perturbations performed in this article can be seen as targeted latent state manipulations. Word2vec
Influence maximization
Adversarial cellular automata have parallels to the field of influence maximization. Influence maximization involves determining the optimal nodes to influence in order to maximize influence over an entire graph, commonly a social graph, with the property that nodes can in turn influence their neighbours. Such models are used to model a wide variety of real-world applications involving information spread in a graph.
For example, in this work, we have made an assumption that our adversaries can be positioned anywhere in a structure to achieve a desired behaviour. A common focus of investigation in influence maximization problems is deciding which nodes in a graph will result in maximal influence on the graph, referred to as target set selection
Discussion
This article showed two different kinds of adversarial attacks on Neural CA.
Injections of adversarial CA in a pretrained Self-classifying MNIST CA showed how an existing system of cells that are heavily reliant on the passing of information among each other is easily swayed by deceitful signaling. This problem is routinely faced by biological systems, which face hijacking of behavioral, physiological, and morphological regulatory mechanisms by parasites and other agents in the biosphere with which they compete. Future work in this field of computer technology can benefit from research on biological communication mechanisms to understand how cells maximize reliability and fidelity of inter- and intra-cellular messages required to implement adaptive outcomes.
The adversarial injection attack was much less effective against Growing CA and resulted in overall unstable CA. This dynamic is also of importance to the scaling of control mechanisms (swarm robotics and nested architectures): a key step in “multicellularity” (joining together to form larger systems from sub-agents
The global state perturbation experiment on Growing CA shows how it is still possible to hijack these CA towards stable out-of-training configurations and how these kinds of attacks are somewhat composable in a similar way to how embedding spaces are manipulable in the natural language processing and computer vision fields