A figure in Ilyas, et. al.
One way to interpret this graph is that it shows how well a particular architecture is able to capture
non-robust features in an image.
Notice how far back VGG
In the unrelated field of neural style transfer
Before proceeding, let’s quickly discuss the results obtained by Mordvintsev, et. al.
Can we reconcile this result with our hypothesis linking neural style transfer and non-robust features?
One possible theory is that all of these image transformations weaken or even destroy non-robust features. Since the optimization can no longer reliably manipulate non-robust features to bring down the loss, it is forced to use robust features instead, which are presumably more resistant to the applied image transformations (a rotated and jittered flappy ear still looks like a flappy ear).
A quick experiment
Testing our hypothesis is fairly straightforward:
Use an adversarially robust classifier for neural style transfer
I evaluated a regularly trained (non-robust) ResNet-50 with a robustly trained ResNet-50 from Engstrom, et.
al.
To ensure a fair comparison despite the different networks having different optimal hyperparameters, I
performed a small grid search for each image and manually picked the best output per network.
Further details can be read in a footnote
The results of this experiment can be explored in the diagram below.
Content image
Style image
Success! The robust ResNet shows drastic improvement over the regular ResNet. Remember, all we did was switch the ResNet’s weights, the rest of the code for performing style transfer is exactly the same!
A more interesting comparison can be done between VGG-19 and the robust ResNet.
At first glance, the robust ResNet’s outputs seem on par with VGG-19.
Looking closer, however, the ResNet’s outputs seem slightly noisier and exhibit some artifacts

Mild artifacts.

Severe artifacts.
It is currently unclear exactly what causes these artifacts.
One theory is that they are checkerboard artifacts
VGG remains a mystery
Although this experiment started because of an observation about a special characteristic of VGG nets, it did not provide an explanation for this phenomenon. Indeed, if we are to accept the theory that adversarial robustness is the reason VGG works out of the box with neural style transfer, surely we’d find some indication in existing literature that VGG is naturally more robust than other architectures.
A few papers
Perhaps adversarial robustness just happens to incidentally fix or cover up the true reason non-VGG
architectures fail at style transfer (or other similar algorithms
To cite Ilyas et al.’s response, please cite their
collection of responses.
Response Summary: Very interesting
results, highlighting the effect of non-robust features and the utility of
robust models for downstream tasks. We’re excited to see what kind of impact
robustly trained models will have in neural network art! We were also really
intrigued by the mysteriousness of VGG in the context of style transfer
Response: These experiments are really cool! It is interesting that preventing the reliance of a model on non-robust features improves performance on style transfer, even without an explicit task-related objective (i.e. we didn’t train the networks to be better for style transfer).
We also found the discussion of VGG as a “mysterious network” really interesting — it would be valuable to understand what factors drive style transfer performance more generally. Though not a complete answer, we made a couple of observations while investigating further:
Style transfer does work with AlexNet: One wrinkle in the idea that robustness is the “secret ingredient” to style transfer could be that VGG is not the most naturally robust network — AlexNet is. However, based on our own testing, style transfer does seem to work with AlexNet out-of-the-box, as long as we use a few early layers in the network (in a similar manner to VGG):

Observe that even though style transfer still works, there are checkerboard patterns emerging — this seems to be a similar phenomenon to the one noticed in the comment in the context of robust models. This might be another indication that these two phenomena (checkerboard patterns and style transfer working) are not as intertwined as previously thought.
From prediction robustness to layer robustness: Another potential wrinkle here is that both AlexNet and VGG are not that much more robust than ResNets (for which style transfer completely fails), and yet seem to have dramatically better performance. To try to explain this, recall that style transfer is implemented as a minimization of a combined objective consisting of a style loss and a content loss. We found, however, that the network we use to compute the style loss is far more important than the one for the content loss. The following demo illustrates this — we can actually use a non-robust ResNet for the content loss and everything works just fine:

Therefore, from now on, we use a fixed ResNet-50 for the content loss as a control, and only worry about the style loss.
Now, note that the way that style loss works is by using the first few layers of the relevant network. Thus, perhaps it is not about the robustness of VGG’s predictions, but instead about the robustness of the layers that we actually use for style transfer?
To test this hypothesis, we measure the robustness of a layer as:
Essentially, this quantity tells us how much we can change the output of that layer within a small ball, normalized by how far apart representations are between images in general. We’ve plotted this value for the first few layers in a couple of different networks below:
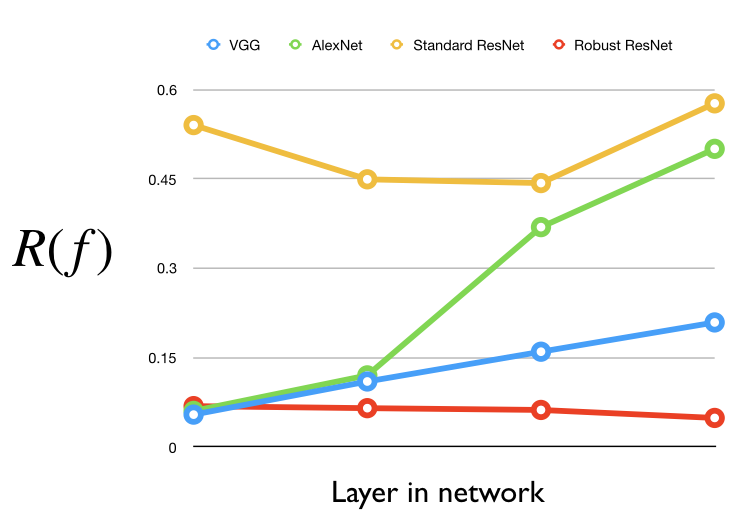
Here, it becomes clear that, the first few layers of VGG and AlexNet are actually almost as robust as the first few layers of the robust ResNet! This is perhaps a more convincing indication that robustness might have something to with VGG’s success in style transfer after all.
Finally, suppose we restrict style transfer to only use a single layer of
the network when computing the style loss
Of course, there is much more work to be done here, but we are excited to see further work into understanding the role of both robustness and the VGG in network-based image manipulation.
You can find more responses in the main discussion article.
This article is part of a discussion of the Ilyas et al. paper “Adversarial examples are not bugs, they are features”. You can learn more in the main discussion article .
Other Comments Comment by Ilyas et al.